-
Key-value store의 일반 특성
NoSQL에는 크게 Key-value, Key-document, Key-column Family, graph 로 나뉜다. 그 중 DynamoDB는 key-value 저장소이며 단순히 get(key)과 put(key,value) 동작만을 지원한다.
value에 해당하는 값은 바이너리 오브젝트이며 데이터베이스에서 봤을 때는 값을 알 수 없는 하나의 덩어리로 보여지게 된다 (불투명하다고 일컬음) 따라서 value에 대한 범위 검색이라던지, 한번의 조회로 value 내용을 이용한 다른 key 검색 둥의 쿼리는 불가능하다. 대신 hash 알고리즘을 이용해 key를 hash값으로 변환하여 값을 찾아가는데 검색 속도가 매우 빠르다.
2. 파티셔닝 알고리즘
DynamoDB에서 get이나 put 요청을 처리하는 노드를 coordinator 노드라고 하는데 요청하는 key에 따라 coordinator 노드가 달라지게 된다. 즉 모든 노드는 특정 key 범위를 처리하도록 역할이 지정되어 있으며 이 범위를 정하는 과정이 파티셔닝 알고리즘이다.
노드 자신이 담당할 key 범위를 정하기 위해선 먼저 노드들의 위치가 정해져야 하는데 이를 위해 노드들은 임의의 일련번호를 받게 된다. (여기서 위치라고 하는 것은 데이터 센터내에 서버의 물리적 위치를 의미하는 것이 아니라 논리적인 위치를 말한다) 일련번호라는 것은 hash 알고리즘을 통해 구해지는데 MD5 hash 알고리즘을 이용해 128bit로 반환되는 함수 값을 의미한다(이후부터는 포지션이라 언급함) Hash 알고리즘의 특징 상 포지션은 임의의 값을 가지게 된다. 포지션대로 일렬로 죽 늘어선 노드를 떠올려 보자. 이제 첫 시작노드와 끝 노드를 이어 붙이면 링 구조가 나오는데 이 링 구조가 노드들의 포지션을 완성한 형태가 된다.
노드들의 위치가 정해졌으면 이제 담당하는 key범위는 어떻게 할당받을까?
put()요청에서 주어진 key 역시 Md5의 Hash 알고리즘 변환을 하게 되며 반환 값을 가지고 링 구조 어딘가에 위치하게 된다. 이 링의 시계방향을 돌며 첫 번째로 마주치는 노드가 바로 coordinator 노드가 된다. coordinator 노드는 오브젝트를 write 하고 옆 노드로 복제본을 전송하는 역할 및 클라이언트에게 OK응답을 보내는 역할을 하게 된다. 아래 그림에서는 key K에 대해 B가 coordinator가 되며 C와 D 노드로 값을 복제하는 역할을 하게 된다.
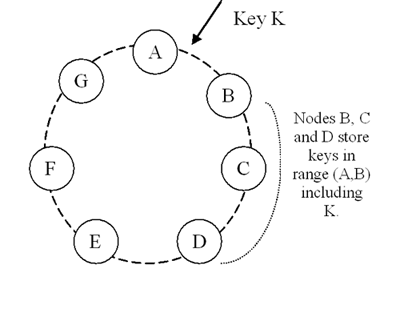
이상 본 것과 같이 노드건 get, put 요청에서 쓰이는 key건 모두 동일한 hashing 알고리즘에 의해 링을 찾아가는 구조임을 알 수 있다. 이러한 이유로 Dynamo에서 파티셔닝 알고리즘은 consistent hashing 기법을 사용한다고 한다.
여기서 한 가지 이슈가 생길 수 있다. 노드의 위치가 랜덤으로 정해지는 과정에서 노드의 분포가 균일하지 않을 수 있다는 것이다. 노드간 간격이 균일해야 노드가 처리하는 부하가 비슷할텐데 어떤 노드 간격은 매우 크고, 어떤 노드 간격은 매우 좁아서 처리량이 다른 결과가 나타날 수도 있다는 것이다. 이를 해결하기 위해 Dynamo는 physical한 노드를 여러개의 논리적인 노드로 나타낸다. 위 그림에서 A부터 G까지 7개의 노드가 있는 것으로 보이지만, 실제로는 3개 혹은 4개의 물리적인 노드가 있을 수도 있는 것이다. 이렇게 물리적인 노드 하나를 여러개의 가상노드로 만듦으로써 평균적으로 노드가 처리해야 할 부하의 양이 비슷해지도록 만든다.
3. 정족수(Quorum)
put 요청을 했을 때 coordinator 노드는 자신에게 write 하고 복제본을 보내 응답을 받아야 하는데, 몇 개의 노드에 복제본을 보내야 할까?
Dynamo에서는 정족수 개념을 사용하는데 N 값은 put 요청시 저장되어야 할 노드의 개수를 의미한다. 즉 coordinator 노드는 자신의 제외한 N-1개의 노드에게 복제본을 전송하여 key를 복사하는 것이다. 위 그림에서 보면 N=3이라고 봤을 때, key K에 대해 노드 B가 노드 C와 D에 복사를 하는 것이다. 이 때 서비스의 응답속도를 위해서 N-1개의 노드로부터의 응답을 모두 기다리지 않는다. N-1보다 작은 W개의 노드로부터만 응답이 오면 정상이라고 판단하고 클라이언트에게 OK 응답을 보내게 된다. 가령 N이 3이고 W가 2라면 coordinator 노드는 자신을 제외한 2개의 노드에 복사를 하지만 일단 1개의 노드로부터 OK응답이 오면 해당 put 요청은 정상 처리가 되었다고 판단하는 것이다. N, W 값 외에 R 값이 존재하는데 R은 읽기 요청에 정상으로 응답하는 최소 노드의 개수를 의미한다. R 값이 2라면 최소 2개 노드로부터 응답이 돌아오면 정상처리 되었다고 판단하고 클라이언트에게 응답하게 된다. R값과 W값의 합이 N값만 넘으면 비둘기집 원리에 의해 read시 적어도 1개의 노드는 최근 값을 리턴하게 된다.
만약 쓰기가 거의 없고 읽기가 대부분이며, 읽기 성능이 매우 중요한 시스템이라면 R을 1, W를 2나 3으로 할 수 있다. 반면 R이 2 또는 3을 가지고 W이 1을 가진다면 어떤 시스템이 될까?
쓰기시 N개의 노드들 중 하나만 응답해도 성공으로 간주하기 때문에 쓰기 성능은 향상되겠지만 읽기시 항상 최소 2개 또는 3개 노드로부터 값을 받아와야 하기 때문에 읽기 성능은 조금 느릴 것이다.
AWS에서 DynamoDB 서비스를 사용해보면 R값과 W값을 입력하도록 되어있는데 각각 9999까지 입력이 가능하다. 그러나 그만큼 비용이 기하급수적으로 늘어나기 때문에 대부분 R과 W를 모두 2로 한다.
4. 버저닝(Versioning)
오브젝트가 Write 될 때 coordinator는 버전을 새겨서 저장하고 이웃한 노드에 복제본을 보낸다. 버전은 Timestamp가 될 수도 있고 카운터가 될 수도 있는데 논문에서는 카운터를 가지고 설명하였으므로 카운터가 어떻게 동작하는지 알아보자.
버전은 [노드, 카운터] 쌍으로 저장된다. 어떤 노드가 update나 insert를 처리하면 자신의 카운터를 하나씩 증가시키는데, 예를 들어 노드 A가 오브젝트X를 저장하였다면 X[A,1] 을 버전으로 저장한다. 이 오브젝트는 노드 B와 C로 전파되어 B와 C 모두 X[A,1] 버전을 가진 오브젝트를 저장하게 된다. 이때 다른 클라이언트가 노드 A에서 이 오브젝트를 업데이트 하였다면 버전은 X[A,2]이 된다. 해당 내용이 다시 B 노드와 C노드로 전파되었다. B와 C는 동일한 key를 가진 기존 오브젝트와 수정된 오브젝트 중 버전이 더 높은 X[A,2]을 확인하고 오브젝트를 덮어쓴다. 이제 새로운 key를 가진 오브젝트Y를 노드B가 coordinator하여 쓴다고 해보자. 여기서 중요한 것은 버전은 모든 오브젝트에 걸쳐 히스토리가 누적되기 때문에 Y[B,1]버전을 갖는것이 아니라 Y[A,2][B,1] 의 버전을 갖게 된다. 따라서 오브젝트의 종류에 상관없이 write된 순서를 대부분 추적할 수 있으며 버전이 충돌되는 경우 last win의 기준을 가지고 더 뒤에 쓰여진 오브젝트를 선택하게 된다. 이것을 구문적(Syntactic) 재조정이라고 하며 대부분의 충돌은 이 방법으로 해결되어 클라이언트의 개입이 필요없게 된다.
그러나 클라이언트가 개입하여 해결해주어야 하는 경우가 있다. 위의 에에서 노드 A가 X[A,2]버전으로 업데이트 한 상황을 다시 생각해보자. 노드B와 C는 모두 X[A,2]버전을 가지고 있는데 어떤 클라이언트는 노드 B를 통해서 값을 업데이트함과 동시에 다른 클라이언트가 동일key에 대해 노드 C를 통해 업데이트를 한다고 생각해보자. B는 X[A,2][B,1]버전을 새긴 후 전파하려고 하는 반면 C는 X[A,2][C,1]을 새겨서 전파하려고 할 것이다. 동일key를 가진 오브젝트로 동시에 업데이트를 하였기 때문에 둘 중 어떤 것이 last인지 알 수가 없는 상황이 된다. 클라이언트가 노드 A를 통해 해당 key로 get하게 되면 충돌된 두 오브젝트를 모두 합친 X[A,2][B,1][C,1]을 볼 수 있도록 하며 이 중 하나를 선택할 수 있게 된다. 이 과정을 의미적(Semantic) 재조정이라고 한다. 하나를 선택하면 노드A는 자신의 노드에 카운터를 하나 증가시켜 X[A,3][B,1][C,1] 버전을 생성한 후 저장한다. 이렇게 재조정된 오브젝트를 노드 B와 C로 다시 전파하며 노드 B와 C는 자신이 갖고 있는 버전보다 높은 버전이기 때문에 의심없이 덮어쓴다.
Dynamo에 대해 설명할 때 약한 일관성을 가진 AP모델이라고 설명하였는데 희생시킨 일관성을 어플리케이션 layer에서 극복하는 것이다.
5. Coordinator 노드의 선정
(1) Preference list
Dynamo에서 정족수 기법을 사용하여 N개의 노드에만 저장을 하고, W개의 노드에서 OK만 되면 put 요청을 완료한 것으로 간주한다고 하였다. 만약 N 노드 중 특정 노드에 장애가 생겨 서비스가 불가한 상황이 생기면 어떻게 될까? 이 문제에 대비하기 위해 항상 N개의 노드가 가용하도록 예비 노드들을 확보하고 있다. 이 리스트를 preference list 라고 한다. 즉 preference list는 특정 key에 대한 read와 write을 처리해야 할 책임이 있는 노드들의 list라고 볼 수 있는데 이 중 정상 동작중인 N개만 get, put 요청에 우선 적용된다고 볼 수 있다.
(2) Coordinator 노드
위 그림(Ring 구조)을 설명할 때 key에 대한 consistent hashing 결과를 링 위에 매핑하여 시계 방향으로 처음 돌다가 마주치는 첫 노드가 coordinator 노드라고 하였는데 사실 항상 그렇지는 않다.
클라이언트가 접근할 때는 두 가지 방식이 있다.
1) 로드 밸런서를 통해 요청을 라우팅해 노드를 선택하는 방법
2) 클라이언트 application에 내장된 library를 통해 직접 코디네이션 노드로 요청을 보내는 방법
1)의 경우는 로드 밸런서는 요청을 아무 노드로 라우팅한다. 이 요청을 받은 노드는 자신이 preference list 중 N 노드 중 하나인지를 확인하며 (뒤에서 설명하겠지만 모든 노드들은 동일한 구성정보를 공유하기 때문에 모든 key에 대한 preference list를 알고있다) 만약 자신이 N 노드 중 하나라면 자신이 coordinator 노드가 된다. 만약 N 노드 중 어떤 노드에도 속하지 않다면 preference list중 가장 위에 있는 노드에게 요청을 전달한다.
2)의 경우는 클라이언트가 내장된 library를 통해 직접 coordinator 노드를 찾아가는데 정확히 어떤 기준으로 coordinator 노드를 찾아가는 것인지는 나와있지 않다. 아마도 그림에서 설명한 것 처럼 시계방향을 따라 이동하다가 마주친 첫 번째 노드라는 것이 이 케이스에 해당하는 것 같다.
장점은 1)에 비해 네트웍 홉(hop)이 줄어들어 속도가 빠르다. 하지만 클라이언트도 노드들의 구성정보를 알고 있어야 하므로 10초에 한번씩 임의의 노드에 접속하여 멤버십 정보를 받아와야 하고 최대 10초간은 잘못된 구성정보를 인지하고 있을 가능성이 있다는 단점이 있다.
