14.1.1 InnoDB as the Default MySQL Storage Engine
InnoDB는 아래와 같은 특징이 있다.
– 트랜잭션이 보장된다(ACID)
– row-level lock이 가능하다.
– 오라클처럼 여러 유저가 동시에 읽는 것이 가능하다(Undo를 이용하여)
– PK에 기반한 공통 쿼리에 대해서는 데이터를 클러스터화된 인덱스에 저장하여 I/O를 절감
– 기본 엔진이기 때문에 테이블 생성시 ENGINE 절을 별도로 명시하지 않으면 기본엔진으로 InnoDB가 선택된다.
InnoDB의 장점
– 서버 Crash 후 기동시 자동으로 복구해준다(redo이용)
– 버퍼 풀을 이용하여 자주 access되는 테이블/인덱스를 캐시할 수 있다.
– PK/FK 등을 이용한 엄격한 스키마 구성이 가능하다.
– 데이터 충돌이 발생하면 checksum 메커니즘에 의해 사용자에게 인폼해준다.
– 테이블에 대해 PK를 구성하면 자동적으로 해당 컬럼은 최적화된다. where, order by, group by, join에서 매우 뛰어난 성능을 발휘할 수 있다.
– change buffering 이라는 메카니즘으로 인해 DML구문이 최적화된다.
– 자주 access되는 row는 adaptive hash index라고 불리는 방식으로 변환되어 마치 hash table에 접근하는 것처럼 접근속도가 더욱 빨라진다.
– 테이블과 인덱스 압축이 가능하다.
– 성능과 가용성에 영향이 덜 가는 인덱스 삭제가 가능하다.
– file_per_table 테이블 스페이스의 truncate가 가능하며 OS에서도 자동 삭제해준다.
– DYNAMIC row형식의 사용으로, BLOB과 Long 텍스트 필드의 저장방식이 더 효과적이다.
– INFORMATION_SCHEMA 테이블을 쿼리함으로써 내부 상황을 모니터링할 수 있다.
최근에 추가된 InnoDB의 개선사항
– FULLTEXT 인덱스 타입을 이용하여 전문검색이 가능하다.
– read-only나 대부분의 read성 워크로드에 더욱 성능이 향상된다. 최적화 자동화는 오토커밋모드의 InnoDB 쿼리에도 적용되며, read-only 트랜잭션은 START TRANSACTION READ ONLY문을 추가함으로써 명시할 수 있다.
– read-only 미디어 기반의 분산 어플리케이션은 이제 InnoDB 테이블을 사용할 수 있다.
InnoDB 테이블의 BP사례
– 모든 테이블에 하나씩 PK를 만들어라. 자주 사용되는 컬럼(들)을 선정하면 좋고, 명확한 PK가 없을 경우에는 자동 증가값을 이용하라.
– 조인의 성능을 향상시키기 위해선 FK 설정을 해라.
– 자동커밋 기능을 꺼버려라. 초당 수백번의 커밋을 찍는 것은 성능에 영향을 미친다.
– DML문을 하나의 트랜잭션으로 묶어라. START TRASACTION AND COMMIT문이 도움이 된다.
– LOCK TABLE 구문을 사용하지 마라. 필요하면 SELECT FOR UPDATE를 써라.
– innodb_file_per_table 옵션을 ON하라.
– InnoDB 테이블을 압축해서 사용하고자 한다면 테스트를 진행해봐라. CREATE TABLE 문에서 ROW_FORMAT=COMPRESSED 옵션을 사용하면 되는데 R/W 성능을 떨어뜨리지 않고도 압축이 가능하다.
– 다른 스토리지 엔진으로 테이블이 생성되는 것을 방지하려면 –sql_mode= NO_ENGINE_SUBSTITUTION 옵션을 사용하라.
14.1.2 Checking InnoDB Availability
현재 서버가 InnoDB를 지원하는지 알아보려면 SHOW ENGINES 명령을 사용하면 된다.
14.1.3 Turning Off InnoDB
InnoDB를 끄는 법은 없다. –skip-innodb, –innodb=OFF 등의 옵션은 무시되고 있다. 반드시 사용해야 하는 스토리지 엔진이다.
14.2 InnoDB Concepts and Architecture
14.2.1 MySQL and the ACID Model
MYSQL은 어떻게 ACID 모델을 구현하고 있는가?
A: 자동커밋도 있고 COMMIT/ROLLBACK 구문도 있다.
C: InnoDB의 doublewrite 버퍼와 충돌 복구기능이 있다.
I: 자동커밋 기능과 ISOLATION LEVEL 구문을 지원한다.
D: innodb_doublewrite 파라미터로 doublewrite 기능 지원
innodb_flush_log_at_trx_commit 파라미터
sync_inlog 파라미터
innodb_file_per_table 파라미터
OS의 fsync() 시스템 콜을 지원
14.2.2 InnoDB Multi-Versioning
InnoDB는 오라클처럼 UNDO 세그먼트를 지원하기 때문에 old version을 볼 수 있다. 내부적으로 InnoDB는 row당 3개의 필드를 추가한다. 6 byte의 DB_TRX_ID 필드는 마지막으로 UPDATE나 INSERT 되었던 트랜잭션 ID를 의미한다. DELETE도 내부적으로는 업데이트된 것으로 인식하며 삭제되었다는 것을 의미하는 별도의 bit를 새겨둔다. 각 row는 roll 포인터라 불리는 7byte의 DB_ROLL_PTR 필드를 가지고 있다. 이 roll 포인터는 사용된 UNDO세그먼트의 포인터를 가리킨다. 6byte의 DB_ROW_ID 필드는 row의 ID를 의미하며 새로운 row가 insert될 때마다 1씩 자동적으로 증가한다. 만약 innoDB가 클러스터된 인덱스를 자동으로 생성했다면 해당 인덱스는 row ID를 가지지만, 이 경우를 제외하고는 어떤 인덱스도 DB_ROW_ID컬럼을 가지지 않는다.
undo 세그먼트는 insert용과 update용으로 나뉜다. insert undo는 오로지 트랜잭션 롤백에서만 의미가 있으며 트랜잭션이 커밋되면 바로 사라진다. update undo는 일관성 읽기에 사용되는데, snapshot이 완료된 직후에 트래잭션이 없는 상황에서만이 폐기될 수 있다.
주기적으로 커밋해야 하며, 그렇지 않으면 InnoDB가 undo log를 폐기할 수 없기 때문에 파일이 비대해질 수 있다. undo 세그먼트에서 undo 레코드의 물리적인 사이즈는 보통 실제 발생된 insert나 update row 보다 작다. SQL 구문에서 delete을 한다고 해서 즉시 값이 물리적으로 제거되는 것은 아니다. delete 내용을 담은 undo 로그 레코드가 폐기 되었을 때 비로소 물리적으로 row와 index의 값을 수정하는 것이다. 이 과정을 purge라고 부르며 꽤 빠르게 진행된다. 거의 delete SQL 구문이 발행되자마자 수행된 것처럼 느낄 정도로 빠르다고 볼 수 있다.
만약 한 테이블에서 insert와 delete를 반복적으로 수행하는 배치를 돌린다면 purge 쓰레드는 점점 뒤쳐질 수 밖에 없고 테이블은 점점 더 불어나게 된다. 이것은 모두 disk 작업으로 향하게 되고 시스템이 매우 느려지는 결과를 초래할 수 있다. 이러한 경우 purge 쓰레드에 좀 더 많은 자원을 투입하도록 파라미터를 수정할 수 있다. innodb_max_purge_lag 변수를 조절하면 된다.
멀티 버저닝과 세컨더리 인덱스
InnoDB의 MVCC는 세컨더리 인덱스를 클러스터된 인덱스와는 다르게 취급한다. 클러스터링된 인덱스는 그 자리에 업데이트되고, 숨겨진 시스템 컬럼이 undo 로그 값을 가리켜서 이전 버전의 레코드 값이 복원될 수 있다. 이러한 클러스터드 인덱스와는 달리 세컨더리 인덱스는 숨겨진 시스템 컬럼이 없기 때문에 적소에 업데이트 되지 않는다.
세컨더리 인덱스의 컬럼이 업데이트되면, old 버전의 레코드 값은 delete 마크가 새겨지고 새로운 값이 insert 되며 delete 마크가 새겨진 레코드는 최종적으로 purge된다. 세컨더리 인덱스 레코드에 delete 마크가 새겨졌거나 새 트랜잭션에 의해 update되었을 경우 InnoDB는 클러스터드 인덱스의 레코드를 살펴본다. 클러스터드 인덱스에서 레코드의 DB_TRX_ID 가 체크되었을 경우 만약 레코드의 값이 읽기 트랜잭션 이후에 수정되었다면 정확한 레코드의 버전을 undo 로그를 통해 복구한다.
세컨더리 인덱스의 레코드에 delete마크가 새겨졌거나 새로운 트랜잭션에 의해 업데이트 되었다면 covering 인덱스 기술(쿼리에 필요한 컬럼이 인덱스에 모두 존재하는 경우 테이블 엑세스 없이 인덱스 lookup만으로 값을 리턴하는 기술)은 사용되지 않는다. 인덱스 구조로부터 값을 돌려주는 대신 InnoDB는클러스터드 인덱스에서 값을 찾아본다.
그러나 만약 인덱스 조건 푸시다운(ICP) 최적화가 적용되었다면, 그리고 where 조건의 일부가 인덱스의 필드에 의해 평가될 수 있다면 MySQL은 where 조건의 일부를 스토리지 엔진으로 푸시 다운한다. 만약 매칭되는 레코드가 없다면 클러스터드 인덱스의 룩업과정은 생략된다. 만약 매치되는 레코드가 발견되면 delete 마크가 새겨져 있다 하더라도 InnoDB는 클러스터드 인덱스의 레코드를 뒤져본다.
14.2.3 InnoDB Redo Log
14.2.3.1 Group Commit For Redo Log Flushing
리두로그는 디스크 상에 존재하는 데이터 구조이며 장애 복구상황에서 완료되지 않은 트랜잭션에 의해 쓰여졌던 데이터를 복구하는데 사용된다. 정상 상황에서 리두 로그는 테이블 구조를 변경하라는 SQL구문이나 Low 레벨의 API로 표현되는 요구사항를 인코딩해둔다. 데이터 파일을 업데이트하려는 수정사항이 완료되지 않은 채 셧다운 되었을 때는 DB가 재시작되고 커넥션을 받기 전에 해당 트랜잭션이 재현된다.
기본적으로 리두로그는 ib_logfile0, ib_logfile1이라는 이름으로 디스크에 존재한다. MySQL은 리두 로그파일을 순환 방식으로 데이터를 write한다. 리두 로그는 영향받는 레코드에 대해 정보를 인코딩하는데 이 데이터를 총괄하여 리두라고 한다. 리두로그를 통한 데이터의 이동은 항상 증가하는 방향의 LSN 값으로 표현된다.
디스크에 존재하는 리두 로그는 아래 옵션을 이용하여 표현된다.
- innodb_log_file_size: 로그 파일 사이즈를 byte 단위로 지정한다. 기본적으로 48MB이다. 이 파라미터와 innodb_log_files_in_group 파라미터 값을 곱한 값이 통합 로그 파일의 사이즈가 되며 이 값은 512GB보다 조금 작다.
- innodb_log_files_in_group: 로그 그룹에 포함될 로그 파일의 개수이다. 기본은 2개.
- innodb_log_group_home_dir: 로그파일의 위치를 설정한다. 기본은 datadir이다.
14.2.3.1 Group Commit for Redo Log Flushing
다른 ACID 지원 데이터베이스 엔진과 같이 InnoDB도 트랜잭션이 커밋되기 전에 redo log를 플러쉬한다. innoDB는 여러 개의 플러쉬 요청을 그룹화함으로써 각각의 커밋에 대한 개별 flush를 회피하는 방식을 사용하고 있으며 이를 그룹 커밋이라고 한다. 그룹 커밋을 이용하면 거의 비슷한 시간대에 발행한 여러 유저의 트랜잭션을 하나의 로그파일 쓰기 요청으로 만들어 수행하며 이것은 성능을 대단히 향상시킨다.
14.2.4 InnoDB Undo Logs
언두 로그는 활성 트랜잭션에 의해 수정된 데이터의 이전 버전을 가지고 있는 스토리지 영역이다. 만약 다른 트랜잭션이 원래의 데이터를 보고자 한다면(일관성 읽기 포함) 이 영역을 통해 수정되지 않은 데이터를 복구할 수 있다. 기본적으로 이 영역은 시스템 테이블스페이스의 일부로써 포함된다. 그러나 MySQL 5.6.3부터 언두로그는 별도의 언두 테이블스페이스에 존재할 수 있다.
InnoDB는 128개의 언두 로그를 지원한다. MySQL5.7.2부터 128개 중 32개의 언두 로그는 임시 테이블 트랜잭션을 위한 non-redo 언두영역으로 예약된 상태로 존재한다. 임시 테이블을 update하는 각 트랜잭션(읽기 전용 트랜잭션은 제외)은 2개의 언두 로그를 할당받는다. 하나는 redo-enabled 된 언두로그이며 하나는 non-redo 언두 로그이다. 읽기 전용 트랜잭션은 오직 임시 테이블을 수정할 수 있는 권한만을 받기 때문에 non-redo 언두 로그만 할당받는다.
남은 96개의 언두 로그들은 각각 데이터를 수정하는 동시 트랜잭션을 1023개 까지 지원할 수 있다. 따라서 대략적으로 96K개 만큼의 데이터 수정 트랜잭션을 동시에 지원할 수 있다고 볼 수 있다. 이 96K 라는 것에 대한 가정은 임시 테이블을 수정하지 않는 트랜잭션에 대한 것이다. 만약 임시 테이블까지도 수정하는 모든 데이터를 수정하는 트랜잭션을 동시에 지원해야 한다면 가능한 트랜잭션은 약 32K 정도가 될 것이다.
14.2.5 InnoDB Temporary Table Undo Logs
MySQL 5.7.2에서 일반 임시테이블, 압축된 임시테이블, 관련된 오브젝트에 대해 새로운 언두로그 타입을 소개했다. 이 새로운 언두로그 타입은 리두 로그가 아닌데 왜냐하면 임시 테이블은 장애 복구가 되지 않기 때문에 리두 로그가 필요 없기 때문이다. 대신 임시테이블 언두로그는 서버가 기동 중인 상황에서 롤백하는데 사용될 수는 있다. 이러한 non-redo 언두로그는 임시테이블과 관련된 오브젝트에 대해 불필요한 redo logging I/O를 줄일 수 있다는 것이 장점이다. 임시 테이블 언두로그는 임시 테이블스페이스에 존재한다. 임시 테이블스페이스는 기본적으로 ibtmp1이며 data 디렉토리에 존재한다. 그리고 서버가 재기동될 때 재생성된다. innodb_temp_data_file_path 파라미터를 통해 임시테이블스페이스 파일의 위치를 결정할 수 있다.
14.2.6 InnoDB Table and Index Structures
14.2.6.1 Role of the .frm File for InnoDB Tables
MySQL은 테이블에 대한 data dictionary를 .frm 파일에 저장한다. 다른 스토리지 엔진과는 달리 InnoDB는 테이블에 대한 정보를 테이블 스페이스 안의 내부적인 데이터 딕셔너리에 저장한다. 만약 테이블이나 database를 드랍할 경우 데이터 딕셔너리에 존재하는 관련된 엔트리들 뿐만 아니라 .frm 파일도 삭제한다. .frm 파일을 옮긴다고 InnoDB의 테이블을 데이터베이스간 옮길 수 있는 것은 아니다.
14.2.6.2 Clustered and Secondary Indexes
모든 InnoDB테이블은 row 데이터를 저장하는 클러스터드 인덱스라 불리는 특별한 인덱스를 가지고 있다. 일반적으로 클러스터드 인덱스는 Primary Key와 동기화된다. insert나 기타 쿼리에 대한 최적의 성능을 발휘하려면 InnoDB가 DML이나 lookup동작을 최적화하기 위해 InnoDB가 클러스터드 인덱스를 어떻게 사용하는지를 잘 파악해야 한다.
- Primary Key를 지정하면 InnoDB는 그것을 클러스터드 인덱스로 사용한다.
테이블 생성시 PK를 지정하면 좋고, 만약 논리적으로 unique하거나 null이 없는 컬럼을 만들기가 힘들다면 값이 자동으로 채워지는 auto-increment 컬럼을 붙여라.
- 만약 Primary Key를 명시적으로 지정하지 않는다면 MySQL은 NOT Null인 첫 번째 Unique 컬럼을 찍어서 클러스터드 인덱스로 지정한다.
- 만약 Primary Key도 없고 적당한 Unique 인덱스도 없다면, InnoDB는 row ID 값을 포함하여 합성된 컬럼을 기반으로 hidden 클러스터드 인덱스를 내부적으로 만들어낸다. InnoDB가 테이블의 각 row에 부여한 ID를 기반으로 row는 정렬된다. 이 row ID는 6byte의 필드로 구성되어 있으며 새로운 row가 insert 될 때마다값이 하나씩 증가한다. 따라서 row ID에 따라 정렬된 row는 물리적으로도 정렬된다.
How the Clustered Index Speeds Up Queries
클러스터드 인덱스에서 인덱스 탐색은 row data가 있는 page로 직접적으로 이어주기 때문에 row 접근이 매우 빠르다. 테이블이 커진 경우에 대해 row data와 인덱스 레코드간 서로 다른 페이지에 저장하는 저장방식과 비교하자면 클러스터드 인덱스의 디스크 I/O가 더 효율적이다. (예를 들어 MyISAM은 데이터 row마다 하나의 file을 사용한다)
How Secondary Indexes Relate to the Clustered Index
클러스터드 인덱스를 제외한 모든 인덱스는 세컨더리 인덱스이다. InnoDB에서 세컨더리 인덱스의 각 레코드는 명시한 컬럼 외에 row에 대한 PK 컬럼을 가지고 있다. InnoDB는 이 PK 값을 이용하여 클러스터드 인덱스에 있는 row 값을 찾는다.
PK 값이 길다면 세컨더리 인덱스는 저장 공간을 더 많이 차지하기 때문에 가급적 PK 길이를 줄이는 것이 좋다.
14.2.6.3 InnoDB FULLTEXT Indexes
전문 인덱스는 텍스트 기반의 컬럼들을(CHAR, VARCHAR, TEXT 컬럼) 기반으로 생성되며 이러한 컬럼에 저장된 데이터에 대한 쿼리와 DML 문의 처리를 빨리 할 수 있도록 한다. ?? stopwords?
전문 인덱스는 CREATE TABLE 문에 추가하여 만들 수도 있고 나중에 ALTER TABLE이나 CREATE INDEX 문으로도 만들 수 있다. 전문 검색은 MATCH()… AGAINST 구문으로 수행된다.
Full-Text Index Design
전문 인덱스는 inverted 인덱스 디자인을 갖고 있다. inverted 인덱스는 단어들의 리스트와 각 단어들이 나타나는 문서의 리스트를 저장한다. 신속한 탐색을 위해 각 단어들의 위치 정보도 함께 1byte로 저장된다.
Full-text Index Tables
InnoDB의 각 전문 인덱스마다 인덱스 테이블 묶음이 생성된다. 아래 예제를 보자.
CREATE TABLE opening_lines (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
opening_line TEXT(500),
author VARCHAR(200),
title VARCHAR(200),
FULLTEXT idx (opening_line)
) ENGINE=InnoDB;
mysql> SELECT table_id, name, space from INFORMATION_SCHEMA.INNODB_SYS_TABLES
WHERE name LIKE 'test/%';
+----------+----------------------------------------------------+-------+
| table_id | name | space |
+----------+----------------------------------------------------+-------+
| 333 | test/FTS_0000000000000147_00000000000001c9_INDEX_1 | 289 |
| 334 | test/FTS_0000000000000147_00000000000001c9_INDEX_2 | 290 |
| 335 | test/FTS_0000000000000147_00000000000001c9_INDEX_3 | 291 |
| 336 | test/FTS_0000000000000147_00000000000001c9_INDEX_4 | 292 |
| 337 | test/FTS_0000000000000147_00000000000001c9_INDEX_5 | 293 |
| 338 | test/FTS_0000000000000147_00000000000001c9_INDEX_6 | 294 |
| 330 | test/FTS_0000000000000147_BEING_DELETED | 286 |
| 331 | test/FTS_0000000000000147_BEING_DELETED_CACHE | 287 |
| 332 | test/FTS_0000000000000147_CONFIG | 288 |
| 328 | test/FTS_0000000000000147_DELETED | 284 |
| 329 | test/FTS_0000000000000147_DELETED_CACHE | 285 |
| 327 | test/opening_lines | 283 |
+----------+----------------------------------------------------+-------+
테이블 생성시 opening_line 컬럼에 대해 전문 인덱스를 만들었다.
그리고 테이블 현황을 보면 처음 6개의 테이블은 inverted 된 인덱스를 의미하며 이것들을 보조 인덱스 테이블이라 한다. 만약 들어오는 문서가 토큰화되면 각 단어들(토큰들이라 부름)은 위치 정보, 그리고 연관된 문서ID(DOC_ID)를 따라 인덱스 테이블로 insert된다.이 단어들은 완전히 정렬되며 character set 정렬인수(weight) 나 단어의 첫 글자에 따라서 여섯 테이블 중 하나로 파티션되어 들어가게 된다.
inverted 인덱스는 병렬 인덱스 생성을 지원하기 위해 여섯개의 보조 인덱스 테이블로 파티션된다. 기본적으로 2개의 쓰레드가 토큰화, 정렬, 단어 및 연관된 데이터에 대한 insert 작업을 담당한다. 쓰레드의 개수는 innodb_ft_sort_pll_degree 파라미터로 지정할 수 있다. 큰 사이즈의 테이블에 대해 전문인덱스를 생성할 경우 쓰레드의 개수를 늘리는 것을 고려해 보아라.
보조 인덱스 테이블은 FTS_로 시작하여 INDEX_로 끝난다. 원본 테이블의 table_id 값을 16진수 값으로 변환한 값을 각 인덱스 테이블의 이름에서 찾아볼 수 있다. 예를 들면 test/opening_lines의 table_id 가 327인데 이것은 16진수로 147이며 이 값은 인덱스 테이블의 이름에서 찾아볼 수 있다.
전문 인덱스에서 16진수로 표현한 index_id 또한 보조 인덱스 테이블에서 찾아볼 수 있다. 예를 들어 test/FTS_0000000000000147_00000000000001c9_INDEX_1 에서 1c9는 10진수로 457이다. INFORMATION_SCHEMA.INNODB_SYS_INDEXES에서 index_id=457로 값을 조회해보면 인덱스를 확인할 수 있다.
mysql> SELECT index_id, name, table_id, space from INFORMATION_SCHEMA.INNODB_SYS_INDEXES
WHERE index_id=457;
+----------+------+----------+-------+
| index_id | name | table_id | space |
+----------+------+----------+-------+
| 457 | idx | 327 | 283 |
+----------+------+----------+-------+
인덱스 테이블은 원본 테이블이 file-per-table일 경우 해당 테이블스페이스에 저장된다.
※ Mysql 5.6.5에서 발견된 버그 때문에 원본 테이블이 file-per-table 에 의해 생성되었더라도 인덱스 테이블은 InnoDB 시스템 테이블스페이스에 저장되었다. 이 버그는 MySQL5.6.20과 5.7.5버전에서 수정되었다. 5.7.8 버전부터는 보조 인덱스 테이블은 항상 원본테이블과 같은 테이블스페이스에 저장되며 원본 테이블과 같은 row 포맷을 같는다.
위 예제에서 본 다른 인덱스 테이블들은 삭제처리나 전문 인덱스의 내부적인 상태를 저장하기 위해 쓰인다.
- FTS_DELETED 와 FTS_DELETED_CACHE: 문서를 삭제하더라도 아직 전문인덱스에서 제거되지 않은 문서들에 대한 ID(DOC_ID)가 저장되는 테이블이다. _CACHE테이블은 _DELETED 테이블의 in-memory 버전이다.
- FTS_*_BEING_DELETED와 FTS_*_BEING_DELETED_CACHE: 전문인덱스에서 현재 삭제가 진행중인 문서의 ID를 저장하는 테이블이다.
- FTS_*_CONFIG: 전문 인덱스의 내부적인 정보를 저장하는 테이블이다. FTS_SYNCED_DOC_ID는 문서를 파싱하고 디스크로 플러쉬한 문서를 식별하는 역할을 하는데 가장 중요한 정보라 할 수 있다. 장애 복구상황에서 이 값을 이용해 디스크로 아직 플러쉬되지 못한 문서들을 식별하고 해당 문서들을 다시 파싱하여 전문 인덱스 캐시로 다시 돌려보낸다. 이 테이블에 있는 데이터들을 보려면 INFORMATION_SCHEMA.INNODB_FT_CONFIG 테이블을 보면 된다.
Full-Text Index Cache
문서가 insert되면 이것이 토큰화되어서 각각의 단어들과 연관된 데이터가 전문 인덱스로 insert된다. 이 과정에서 작은 크기의 문서라도 보조 인덱스 테이블로 많은 insert가 발생하게 되어 경합이 발생하게 된다. 이 문제를 피하기 위해, innoDB는 전문 인덱스를 캐싱하여 최근 insert된 row에 대해 캐싱된 인덱스 테이블을 이용한다. 이런 인메모리 캐시 구조는 캐시가 꽉 차거나 주기적으로 disk로 플러쉬시킬 때까지 insert 트랜잭션을 유지하게 된다. INFORMATION_SCHEMA.INNODB_FT_INDEX_CACHE 테이블이 최근 insert된 row에 대해 토큰화된 데이터를 볼 수 있게 해준다.
캐싱과 배치 플러쉬 방식은 insert나 update가 빈번할 때 경합을 발생시킬 수도 있을 만한 보조 인덱스 테이블로의 빈번한 업데이트 작업을 줄여준다. 또한 이 방식은 동일한 단어에 대한 반복적인 insert 작업을 줄여주게 되고 중복된 엔트리 생성을 최소화해준다. 각각의 단어마다 플러쉬하는 대신 동일한 word에 대한 insert 는 하나로 합해져 단일의 엔트리로써 디스크로 플러쉬된다. 따라서 임시테이블을 가능한 한 작게 유지하는 반면 효율을 높을 수도 있다.
innodb_ft_cache_size 변수는 전문 인덱스의 캐시 사이즈(기본적으로 테이블 당)를 조절할 수 있는데 이는 전문 인덱스 캐시가 얼마나 자주 플러쉬 되는지를 결정하게 된다. 또한 innodb_ft_total_cache_size 파라미터를 통해 전체 테이블에 걸쳐 사용되는 글로벌 전문인덱스의 캐시 사이즈를 정할 수 있다.
전문 인덱스 캐시는 임시 테이블과 동일한 정보를 저장한다. 그런데 전문 인덱스 캐시는 최근 insert된 row에 대해 토큰화된 데이터만 저장한다. 즉 이미 디스크(임시 전문테이블)로 플러쉬된 데이터는 나중에 쿼리된다 하더라도 캐시로 올라오지 않는다. 보조 인덱스 테이블에 있는 데이터는 직접적으로 조회되고 보조 인덱스 테이블에서의 결과물은 전문 인덱스 캐시에 있는 값과 합쳐져서 반환된다.
InnoDB Full-Text Document ID and FTS_DOC_ID Column
InnoDB는 전문 인덱스에 있는 단어와 문서에서 실제 나타나는 구간을 매핑하기 위해 유일한 값을 갖는 ID (DOC_ID) 라고 불리는 식별자를 이용한다. 매핑을 위해선 원본 테이블의 FTS_DOC_ID 컬럼이 필요하다. 만약 FTS_DOC_ID 컬럼이 정의되지 않았다면 InnoDB는 전문 인덱스 생성시 숨겨진 상태로 이 컬럼을 자동 생성한다. 아래 예제는 이런 특징을 보여준다.
CREATE TABLE opening_lines (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
opening_line TEXT(500),
author VARCHAR(200),
title VARCHAR(200)
) ENGINE=InnoDB;
만약 CREATE FULLTEXT INDEX 키워드를 통해 전문 인덱스를 생성한다면, FTS_DOC_ID 컬럼을 추가하기 위해 테이블을 리빌딩했다는 경고 메시지를 받게 된다.
mysql> CREATE FULLTEXT INDEX idx ON opening_lines(opening_line);
Query OK, 0 rows affected, 1 warning (0.19 sec)
Records: 0 Duplicates: 0 Warnings: 1
mysql> SHOW WARNINGS;
+---------+------+--------------------------------------------------+
| Level | Code | Message |
+---------+------+--------------------------------------------------+
| Warning | 124 | InnoDB rebuilding table to add column FTS_DOC_ID |
+---------+------+--------------------------------------------------+
ALTER TABLE 문을 이용하여 전문 인덱스를 생성하려고 했을 때도 마찬가지의 경고를 받게 된다. 만약 별도의 FTS_DOC_ID 컬럼을 만들지 않았으나 CREATE TABLE 문을 이용하여 전문 인덱스를 생성하면 경고 없이 숨겨진 FTS_DOC_ID 컬럼을 만들어낸다.
CREATE TABLE시 FTS_DOC_ID 컬럼을 정의하는 것은 이미 데이터가 있는 테이블에서 전문 인덱스를 생성하는 것보다 시간이 더 적게 걸린다. 당연하겠지만 데이터를 로드하기 전에 테이블에 FTS_DOC_ID 컬럼이 정의되어 있다면 테이블과 인덱스는 리빌드될 필요가 없다. 만약 CREATE FULLTEXT INDEX 의 성능이 걱정된다면 InnoDB가 알아서 하도록 그냥 냅둬라.
InnoDB가 FTS_DOC_ID 컬럼과 그에 기반한 unique 인덱스를 생성한다.(FTS_DOC_ID_INDEX) 만약 FTS_DOC_ID를 직접 정의하고 싶으면 아래와 같이 반드시 BIGINT UNSIGNED NOT NULL 속성과 함께 FTS_DOC_ID로 네이밍해야 한다.
CREATE TABLE opening_lines (
FTS_DOC_ID BIGINT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
opening_line TEXT(500),
author VARCHAR(200),
title VARCHAR(200)
) ENGINE=InnoDB;
※FTS_DOC_ID 컬럼을 꼭 AUTO_INCREMENT 속성으로 만들 필요는 없지만 데이터를 로딩을 더욱 쉽게 해준다.
FTS_DOC_ID 컬럼을 직접 생성했다면 null 값이나 중복된 값을 회피하기 위한 관리를 직접 해주어야 한다. FTS_DOC_ID 값은 재사용될 수 없으며 항상 증가하는 방향이어야 한다. 추가적으로 FTS_DOC_ID_INDEX 인덱스도 직접 만들 수 있으며 직접 만들지 않으면 InnoDB가 알아서 만들어준다.
InnoDB Full-Text Index Deletion Handling
전문 인덱스 컬럼에서 값을 삭제하면 보조 인덱스 테이블에서 몇 번의 작은 삭제작업이 발생하게 되며 이것 또한 경합을 일으킬 소지가 있다. 이 문제를 피하고자 원본 테이블의 레코드가 삭제되면 삭제된 문서의 DOC_ID가 FTS_*_DELETED 테이블에 기록되는 반면 전문 인덱스에는 남아있게 된다. 쿼리 결과가 반환되기 FTS_*_DELETED 테이블을 찾아 삭제된 문서를 필터링한다. 이 방식의 장점은 삭제 작업이 빠르고 비용이 적게 든다는 것이다. 이 방식의 결점은 삭제작업 후 인덱스가 바로 삭제되지 않는 다는 것이다. 전문 인덱스의 엔트리에서 값을 삭제하기 위해선 innodb_optimize_fulltext_only=ON 으로 설정한 상태에서 OPTIMIZE TABLE을 돌려줘야 전문인덱스가 리빌딩되면서 값이 삭제된다.
InnoDB Full-Text Index Transaction Handling
전문인덱스가 가진 캐싱과 배치 플러쉬 특성 때문에 트랜잭션이 매우 특이하게 처리된다. 특히 전문 인덱스에 대한 update와 insert는 트랜잭션의 commit단계에서 발생하며 이것은 전문인덱스에 대한 정보는 오직 committed 데이터만 볼 수 있다는 것을 의미한다.
14.2.6.4 Physical Structure of an InnoDB Index
공간인덱스를 제외하면 InnoDB의 인덱스는 모두 B-tree 구조이다. 공간 인덱스는 R-tree 구조를 사용하며 이것은 다차원 구조로 인덱싱된 데이터 구조를 가지고 있다.B-tree, R-tree구조 모두 인덱스 레코드는 leaf 페이지에 저장되며 기본적인 페이지의 크기는 16KB이다.
클러스터드 인덱스에 새로운 레코드가 insert되면 innoDB는 차후에 insert되거나 update 될 때를 대비하여 페이지의 1/16은 남겨놓는다. 만약 연속적인 값이 insert된다면 인덱스 페이지는 15/16이 사용될 것이며, 랜덤하게 값이 들어온다면 인덱스 페이즈는 1/2 에서 15/16 사이를 사용하게 될 것이다.
Mysql 5.7.5부터 B-tree 인덱스를 생성하거나 리빌드할 때 벌크 load를 수행한다. 이런 인덱스 생성 방식은 정렬된 인덱스 생성이라고 알려져 있다. innodb_fill_factor 파라미터는 정렬된 인덱스 생성을 수행하는 동안 인덱스 페이지가 얼마나 채워질지를 결정한다. (MariaDB에 이 파라미터는 없음) 남은 공간은 차후 인덱스가 늘어날 때 사용된다. 정렬된 인덱스 생성방식은 공간 인덱스에는 지원되지 않는다.
만약 인덱스 페이지에 대한 fill factor가 MERGE_THRESHOLD(기본적으로 50%) 이하로 떨어지면 InnoDB는 인덱스 크기를 줄이게 된다. MERGE_THRESHOLD 값은 B-tree와 R-tree에 모두 영향을 준다.
인스턴스를 생성하기 전에 innodb_page_size 파라미터를 셋팅함으로써 인스턴스의 모든 InnoDB 테이블스페이스 페이지 사이즈를 정할 수 있다. 인스턴스에서 한번 셋팅되면, 다시 바꿀 수는 없다. 지원되는 사이즈는 64KB, 32KB, 16KB(기본 값), 8KB, 4KB이다.
14.2.6.5 Change Buffer
변경 버퍼는 세컨더리 인덱스 페이지의 변경사항이 발생했을 때 해당 페이지가 버퍼 풀에 존재하지 않으면 변경 내용을 캐싱하는 특별한 데이터 구조이다.
DML 구문으로 인해 버퍼된 변경사항은 나중에 읽기 동작으로 인해 페이지가 버퍼 풀로 로딩되면서 합쳐지게 된다.
클러스터드 인덱스와는 다르게 세컨더리 인덱스는 보통 non-unique하며 세컨더리 인덱스로의 insert는 상대적으로 랜덤한 순서를 가진다. 마찬가지로 delete와 update 가 수행되면 인덱스 트리의 인접한 위치의 인덱스 페이지에 영향을 미치는 것이 아니다. 다른 읽기 트랜잭션에 의해 해당페이지가 버퍼 풀로 로딩되었을 때 변경사항을 취합하여 저장하게 된다. 이것은 세컨더리 인덱스 페이즈를 디스크로부터 읽어들이기 위한 랜덤 엑세스를 줄여주게 된다.
시스템이 거의 idle 상태이거나 slow shutdown 상태가 되면 주기적으로 업데이트된 인덱스 페이지를 디스크로 내려쓰는 purge 동작을 수행한다. 이런 purge 동작은 연속적인 인덱스 값을 따라 디스크 블록에 저장하므로 수정사항이 발생할 때마다 디스크에 바로바로 쓰는 것보다 효율적으로 움직이게 된다. 세컨더리 인덱스의 개수가 많은 경우나 영향받은 row의 수가 많을 경우에 변경 버퍼를 취합하는 것은 몇 시간이 걸릴 수도 있다. 이 동안 디스크 사용율이 늘어나 disk작업이 수반되는 쿼리의 성능을 저하시킬 수 있다. 변경 버퍼의 취합과정은 트랜잭션이 커밋된 이후에도 지속되는데 사실 변경 버퍼의 취합은 서버가 셧다운되거나 리스타트 된 이후에도 지속된다.
메모리안에서 변경 버퍼는 InnoDB 버퍼 풀의 일부를 복사한다. 디스크에서 변경 버퍼는 시스템 테이블스페이스의 일부이기 때문에 DB가 재시작 된 이후에도 인덱스 변경 사항이 버퍼링될 수 있는 것이다. 변경 버퍼에 캐시되는 데이터의 유형은 innodb_change_buffering 파라미터에 의해 결정된다.
Monitoring the Change Buffer
(1) mysql> SHOW ENGINE INNODB STATUS\G
위 명령을 수행했을 때 나타나는 정보 중 INSERT BUFFER AND ADAPTIVE HASH INDEX 항목에서 관련 내용을 찾아볼 수 있다.
(2) INFORMATION_SCHEMA.INNODB_METRICS 테이블에서도 찾아볼 수 있다.
mysql> SELECT NAME, COMMENT FROM INFORMATION_SCHEMA.INNODB_METRICS WHERE NAME LIKE '%ibuf%'\G
(3) INFORMATION_SCHEMA.INNODB_BUFFER_PAGE 테이블에서도 관련 정보를 찾아볼 수 있다. 이 테이블은 버퍼 풀에 존재하는 페이지에 대한 메타 정보를 담고있는데 변경 버퍼 인덱스와 변경 버퍼 비트맵 페이지도 포함하고 있다. 인덱스 페이지에 대한 변경 버퍼 페이지는 PAGE_TYPE 컬럼이 IBUF_INDEX 라고 되어 있다. IBUF_BITMAP은 변경 버퍼 비트맵에 대한 페이지를 나타낸다.
변경 버퍼 페이지가 버퍼 풀의 몇 %를 차지하고 있는지를 확인하려면 아래 쿼리를 이용한다.
SELECT
(SELECT COUNT(*) FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGE
WHERE PAGE_TYPE LIKE 'IBUF%'
) AS change_buffer_pages,
(
SELECT COUNT(*)
FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGE
) AS total_pages,
(
SELECT ((change_buffer_pages/total_pages)*100)
) AS change_buffer_page_percentage;
(4) PERFORMANCE_SCHEMA.SETUP_INSTRUMENTS
아래와 같이 쿼리하여 mutex wait 정보를 볼 수 있다.
mysql> SELECT * FROM performance_schema.setup_instruments WHERE NAME LIKE ‘%wait/synch/mutex/innodb/ibuf%’;
14.2.6.6 Adaptive Hash Indexes
Adaptive Hash Indexes(이하 AHI)는 매우 큰 버퍼 풀 공간과 다양한 워크로드의 조합을 기반으로 in-memory 데이터베이스처럼 동작하는데 트랜잭션의 특성이나 안정성을 훼손하지 않고도 동작 가능하다. innodb_adaptive_hash_index 파라미터를 통해 설정 가능하다.
검색 패턴을 관찰한 내용을 기반으로 하여 MySQL은 인덱스 key의 prefix를 이용하여 해쉬 인덱스를 만든다. key의 prefix의 길이에 대한 제한은 없으며, B-tree 값 중 몇 개의 값만 대상으로 해쉬 인덱스를 만들게 된다. 해쉬 인덱스는 자주 엑세스되는 인덱스 페이지에 대한 요청에 의해 생성된다.
만약 테이블 전체가 메모리 안에 상주해 있다면, 해쉬 인덱스는 어떤 값이든지 직접적으로 빠르게 값을 찾아보게 된다. InnoDB는 인덱스 탐색과정을 모니터링하는 메커니즘을 갖고 있으며 만약 해쉬인덱스를 만드는 것이 이득이라고 판단하면 자동적으로 만들어낸다.
어떤 특정한 워크로드에서는, 인덱스 모니터링이나 해쉬인덱스를 유지하는 등의 추가적인 부담으로 인해 해쉬인덱스를 사용하는 것이 시스템 부담이 더 커질수도 있다. 다차원 join이 동시다발적으로 일어나는 무거운 워크로드 하에서는 해쉬인덱스로의 접근을 통제하는 read/write lock이 경합을 일으키는 원인이 될 수 있다. LIKE 구문이나 % 와일드 카드를 사용하는 쿼리 또한 AHI를 제대로 사용하지 못하므로 AHI가 필요없는 워크로드에서는 이 기능을 꺼버리는 것이 불필요한 성능 오버헤드를 줄여주는 요인이 된다. 특정 시스템에서 이 기능을 쓰는 것이 좋은지 아닌지 판단하기가 힘들기 때문에 이 기능을 ON/OFF 하고 벤치마크 테스트 하는 것을 고려해보아라. MySQL 5.6이나 그 이상 버전에서는 대부분의 워크로드가 이 기능을 끄는 것이 오히려 더 좋게 변화되었다. 그러나 아직 디폴트로 이용하도록 되어있다.
MySQL 5.7.8 부터 AHI는 파티셔닝이 가능하다. 각 인덱스는 특정한 파티션에 소속되며 각 파티션은 별도의 latch에 의해 관리된다. innodb_adaptive_hash_index_partitions 파라미터에 의해 파티셔닝 개수를 조절할 수 있다. 이전 버전에서는 단 하나의 latch에 의해 AHI를 관리하였으므로 무거운 워크로드 하에서는 경합의 주 원인이 되었었다.
SHOW ENGINE INNODB STATUS 명령으로 AHI의 사용현황과 경합 발생 현황까지 볼 수 있다.(SEMAPHORES 섹션) 만약 btr0sea.c 에서 RW 래치를 대기하는 쓰레드의 수가 많다고 판단되면 AHI 기능을 끄는 것이 좋다.
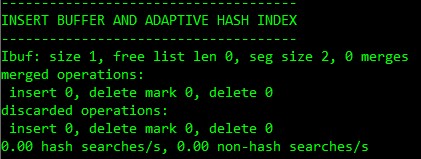
< INNODB STATUS 의 AHI 섹션>

< INNODB STATUS 의 SEMAPHORE 섹션>
14.2.6.7 Physical Row Structure
테이블의 물리적인 구성방식은 테이블 생성시 어떤 row 포맷으로 지정했느냐에 따라 다르다. 별도로 지정하지 않았을 경우 디폴트 row 포맷이 적용되는데 MySQL 5.7.6 버전 이전에서는 Antelope 라는 파일포맷과 이것의 COMPACT row 포맷이 기본적으로 적용되었다. MySQL 5.7.7 에서는 innodb_file_format 파타미터에 의해 기본적으로 Barracuda가 적용되었고 5.7.9 부터는 innodb_default_row_format 파라미터에 의해 결정되고 있다. 이 파라미터의 기본 값은 DYNAMIC이다. 현재 MariaDB는 innodb_file_format 파라미터에 의해 결정되고 있으며 기본 값은 antelope이다. (버전 10.1.12)
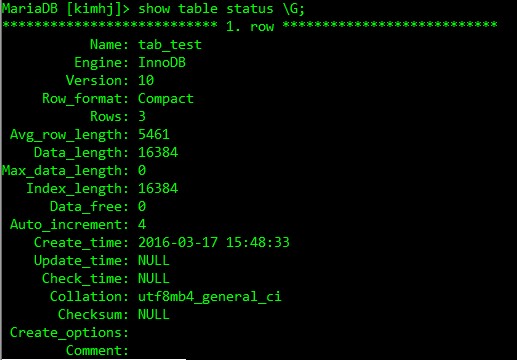
<COMPACT row 포맷>
COMPACT row 포맷은 CPU성능을 좀 더 필요로 하는 대신 저장 공간을 20% 이상 절감한다. 만약 워크로드가 캐시 hit율과 disk speed에 의해 병목이 생기는 시스템이라면 COMPACT row 포맷은 좀 더 빠르게 작동한다. 그러나 CPU speed가 병목을 유발하는 시스템이라면 COMPACT row 포맷은 좀 더 느리게 작동한다.
REDUNDANT row 포맷을 사용하는 InnoDB의 row는 아래와 같은 특징을 가진다.
- 각 인덱스 레코드는 6byte의 헤더를 갖는다. 이 헤더는 연속적인 레코드를 서로 이어주는데 사용되며 저단계 locking에 사용된다.
- 클러스터드 인덱스는 유저가 정의한 모든 컬럼을 갖는다. 추가적으로 6 byte의 트랜잭션ID 필드와 7 byte의 roll pointer 필드를 갖는다.
- 테이블에 대해 PK가 정의되지 않는다면 각 클러스터드 인덱스는 6byte의 ROW ID 필드를 갖는다.
- 모든 세컨더리 인덱스는 클러스터드 인덱스에서 정의되었지만 세컨더리 인덱스에서는 정의되지 않은 PK컬럼을 내부적으로 포함하고 있다.
- 각 레코드는 서로를 가리키는 포인터를 가지고 있다. 만약 레코드의 전체 길이가 128byte 이내라면 포인터는 1byte가 되며 그렇지 않으면 2byte가 된다. 이 pointer의 배열을 레코드 디렉토리라고 부른다. 이 포인터가 가리키는 영역을 레코드의 데이터 파트라고 한다.
- Null 값에는 1byte나 2byte의 공간을 레코드 디렉토리에 예약해둔다. 게다가 Null 값은 해당 필드가 가변길이 컬럼으로 정의되어 있으면 데이터 파트에는 공간을 예약해두지 않는다. 고정 길이 컬럼에는 데이터 파트에는 해당 길이만큼 공간을 예약해둔다. 이 예약방식 덕분에 non-null 값으로 차후 업데이트 되어도 페이지의 조각화를 유발하지 않게 된다.
COMPACT row format을 갖는 InnoDB의 row는 아래와 같은 특징을 가진다.
- 각 인덱스 레코드는 5byte의 헤더를 가지며 가변길이 헤더와 별도로 미리 생성된다. 또한 이 헤더는 연속한 레코드들 간 서로 연결하기 위해 쓰이며 저레벨 locking에 사용된다.
- 레코드 헤더의 가변길이 파트는 Null 컬럼을 가리키기 위한 bit 벡터를 가진다. 인덱스에서 null 값을 가질 수 있는 컬럼의 개수가 N일 때 9<= N <=15 라면 bit 벡터는 2byte의 크기가 된다. null인 컬럼은 bit vector 외엔 공간을 차지하지 않는다. 헤더의 가변길이 파트는 가변길이 컬럼에 대한 length를 가진다. 각 length는 가변길이 컬럼의 최대 값에 따라 1byte 또는 2byte를 갖는다. 만약 인덱서의 모든 컬럼이 Not null 이고 고정된 길이를 가진다면 레코드 헤더는 가변길이 파트를 가지지 않는다.
- not null인 가변길이의 각 컬럼에 대해, 레코드 헤더는 1byte 혹은 2byte의 컬럼에 대한 ??을 갖는다. ???
- null값이 아닌 데이터 뒤에 레코드 헤더가 뒤따라온다.
- 클러스터드 인덱스는 유저가 정의한 모든 컬럼을 갖는다. 추가적으로 6 byte의 트랜잭션ID 필드와 7 byte의 roll pointer 필드를 갖는다. (REDUNDANT와 동일)
- 테이블에 대해 PK가 정의되지 않는다면 각 클러스터드 인덱스는 6byte의 ROW ID 필드를 갖는다. (REDUNDANT와 동일)
- 세컨더리 인덱스의 각 레코드는 해당 인덱스에선 정의되진 않았지만 클러스터드 인덱스에 정의되어 있는 PK값을 가지고 있다. 만약 PK 컬럼이 가변길이 특성을 갖고 있다면, 세컨더리 인덱스가 고정길이 컬럼에 기반하여 생성되었더라도 이 레코드 헤더 또한 length를 기록하기 위한 가변길이 파트를 보유한다.
- 내부적으로 InnoDB는 CHAR(10)같은 고정길이의 컬럼에 대해 고정 길이만큼 저장한다. VARCHAR 컬럼에 대해선 trailing한 공간은 truncate하지 않는다.
- SQL null 값에 대해 레코드 디렉토리에 1byte나 2byte의 공간을 남겨둔다. 게다가 null 값은 가변길이 컬럼에 대해선 데이터 파트에 공간을 하나도 남겨두지 않는다. 고정길이 컬럼에 대해서는 데이터 파트에 고정 길이만큼 공간을 남겨둔다. 차후 null이 아닌 값이 update되는 상황을 위해 특정 길이의 공간을 남겨두는 것은 페이지의 조각화를 방지해준다.
- 내부적으로 InnoDB는 utf8의 CHAR 컬럼과 uft8mb4의 CHAR(N) 컬럼의 데이터는 N byte만큼 지저분한 공간들을 정리하여 저장한다. 만약 CHAR(N)의 바이트 길이가 N 바이트를 초과하면 InnoDB는 바이트 길이를 최소화하기 위해 지저분한 공간들을 정리한다. CHAR(N)의 최대 길이는 character 바이트 길이 * N 과 동일하게 되며 INFORMATION_SCHEMA.COLUMNS 테이블의 CHARACTER_OCTET_LENGTH 컬럼의 값에서 내용을 확인할 수 있다.
InnoDB는 CHAR(N)에 대해 최소 N 바이트는 예약해둔다. N 바이트만큼 예약함으로써 차후 update가 될 때 페이지의 조각화가 되는 것을 방지하게 된다.
대조적으로 ROW_FORMAT 이 REDUMDANT인 경우 utf8과 utf8mb4 컬럼은 character 바이트 길이*N 길이만큼 미리 할당해두며 ROW_FORMAT이 DYNAMIC인 경우와 COMPRESSED인 경우는 COMPACT인 경우와 동일하게 작동한다.
DYNAMIC과 COMPRESSED row 포맷은 COMPACT의 변형된 포맷이다.
14.2.6.8 Sorted Index Builds
MySQL 5.7.5부터 인덱스를 생성하거나 리빌드할 때 한번에 레코드 하나씩 insert하는 것이 아니라 대량으로 로딩하는 방법을 사용한다. 이러한 방식의 인덱스 생성기법을 정렬된 인덱스 생성이라고 부른다. 정렬된 인덱스 생성기법은 공간 인덱스에서는 지원되지 않는다.
인덱스를 생성하는 과정은 크게 3가지로 나뉜다. 첫 번째 단계에서는 클러스터드 인덱스를 스캔한 후 인덱스 엔트리를 생성하여 sort 버퍼에 넣어둔다. sort 버퍼가 꽉 차면 엔트리들을 정렬시킨 후 임시 파일에 내려쓴다. 이 과정을 “run”이라고 부른다. 두 번째 단계에서는 첫 번째 단계에서 한번 이상 임시 파일에 내려 쓴 것들을 모두 모아 전체 엔트리를 대상으로 전체 정렬을 수행한다. 세 번째 단계에서는 정렬된 엔트리들이 B-tree로 insert된다.
정렬된 인덱스 생성기법이 소개되기 전에는 insert API를 이용하여 한번에 레코드 하나씩 B-tree로 삽입하는 방법을 사용했었다. 이 방법은 insert할 위치를 찾고 낙관적 insert 방식으로 엔트리를 B-tree 페이지 안으로 넣기 위해 B-tree의 커서를 오픈해야 했다. 만약 page가 full로 인해 insert가 실패한다면 비관적 insert 방식이 수행되었는데 이 방식은 엔트리의 저장 공간을 찾기 위해 B-tree의 커서를 오픈하고 B-tree의 노드를 분할, 합병하는 방식으로 진행되었다. 이러한 Top down 방식의 단점은 insert 위치를 찾는데 소모되는 비용과 지속적인 B-tree 노드의 분할, 합병이 발생한다는 점이다.
정렬된 인덱스 생성 기법은 bottom up 방식을 채택하고 있다. 이 방식에서는 B-tree의 모든 레벨에서 가장 우측에 있는 leaf 페이지를 기준으로 삼아, ???
Reserving B-tree Page Space for Future Index Growth
향후 인덱스의 증가에 대비해서, innodb_fill_factor 파라미터를 통해 B-tree 페이지의 여분 공간을 정할 수 있다. 예를 들어 이것을 80으로 한다면 정렬된 인덱스 생성 중 페이지의 20%는 여유공간으로 남겨둔다. 이 방식은 B-tree leaf와 non leaf 페이지에 모두 적용된다. 그러나 이것은 TEXT나 BLOB엔트리를 위해 저장하는 외부 페이지에 대해서는 적용되지 않는다. 그리고 여분 공간의 사이즈는 정확하게 지켜지지 않는다. innodb_fill_factor 파라미터는 명확한 규율이라기 보다는 힌트에 가깝다.
Sorted Index Builds and Fulltext Index Support
정렬된 인덱스 생성기법은 전문 인덱스에서도 지원된다. 엔트리를 전문 인덱스로 insert 하도록 SQL이 미리 이용된다.
Sorted Index Builds and Compressed Tables
압축된 테이블에서 이전의 인덱스 생성 방식은 압축되거나 혹은 압축되지 않은 페이지에 엔트리를 덧붙였었다. 만약 수정 로그(압축된 페이지에서 여유 공간을 나타냄)가 꽉 차게 되면 압축된 페이지는 다시 압축되었다. 만약 공간 부족을 이유로 압축이 실패하게 되면 페이지는 쪼개진다. 정렬된 인덱스 생성방식에서 엔트리는 압축되지 않은 페이지에만 덧붙여지게 된다. 압축되지 않은 페이지가 꽉 차게 되면 이 페이지는 압축된다. 압축이 대부분의 케이스에서 성공적으로 끝났다는 것을 확실하게 하기 위해 적응적 덧붙임 방식이 사용되지만, 압축이 실패로 끝난 경우 페이지는 쪼개지며 압축이 재실행된다. 이 과정은 압축이 정상적으로 끝날 때까지 지속된다.
Sorted Index Builds and Redo Logging
정렬된 인덱스 생성중에는 리두 로깅이 중단된다. 대신에 인덱스 생성과정이 장애 상황에 대비할 수 있도록 체크포인트가 존재한다. 체크포인트는 모든 dirty 페이지를 디스크에 내리도록 강제한다. 정렬된 인덱스 생성중에 체크포인트 동작이 빨리 수행될 수 있도록 page cleaner 쓰레드가 주기적으로 신호를 받아 dirty 페이지를 플러시한다. 보통 page cleaner 쓰레드는 clean 페이지의 개수가 특정 임계치 값 이하로 내려가면 작동되는데 정렬된 인덱스 생성중에는 병렬I/O와 CPU그리고 체크포인트의 오버헤드를 줄이기 위해 dirty 페이지들이 신속히 플러시된다.
Sorted Index Builds and Optimizer Statistics
정렬된 인덱스 생성방식은 이전의 생성방식과는 다른 옵티마이저 통계정보를 생성해낼 수 있다. 인덱스를 생성하는 알고리즘이 다르기 때문에 이런 일이 발생하는데 워크로드에 어떤 영향을 미칠지 예상할 수는 없다.
14.2.7 InnoDB Mutex and Read/Write Lock Implementation
MySQL과 InnoDB에서 여러 개의 쓰레드가 공유 구조체에 접근한다. InnoDB는 읽기/쓰기 락과 자체구현한 뮤텍스로 이러한 접근들을 동기화한다. 전통적으로 InnoDB는 읽기/쓰기 락의 내부 상태를 뮤텍스로 보호했었다. 그리고 이 뮤텍스는 P쓰레드 뮤텍스라고 하는 것에 의해 보호되었다.
많은 플랫폼에서 P쓰레드보다는 원자적 수행으로 여러 개의 쓰레드를 동기화하는 방안이 더 효율적으로 사용되곤 하였다. 락을 얻거나 해제하려는 각각의 시도들은 CPU를 더 적게 소모하였고 쓰레드가 공유 데이터 구조체에 접근하려고 경쟁하는 시간도 더 단축하게 되었다. 이것은 결국 멀티 코어플랫폼에서는 더욱 큰 확장성을 가져다 준다는 것을 의미한다.
원자적 수행을 지원하는 플랫폼에서 InnoDB는 빌트인된 GNU 컴파일러 컬렉션(GCC)로 만들어진 뮤텍스와 읽기/쓰기 락을 구현하였으며 원자적 메모리 접근 상황하에서 P쓰레드 방식 대신 사용되고 있다. 더군다나 GCC 버전 4.1.2 이상에서 컴파일된 InnoDB의 경우 뮤텍스와 읽기/쓰기 락을 구현하기 위해 pthread_mutex_t 대신 내장된 빌트인을 사용하고 있다.
32비트의 윈도우즈의 경우, InnoDB는 뮤텍스(읽기/쓰기 락은 아닌)를 직접쓰기 어셈블러 방식으로 구현하였다. 윈도우즈 2000이 시작될 때 interlocked variable access 함수가 가능했었는데 이것은 GCC에 의해 제공되던 내장함수와 비슷하였다. 윈도우 2000 이후부터는 InnoDB는 읽기/쓰기 락과 64비트 플랫폼을 지원하는 interlocked 함수를 사용하였다.
솔라리스10은 원자적 동작에 대한 라이브러리 함수를 제공하였으며 InnoDB는 이 방식을 디폴트로 사용하였다. MySQL이 솔라리스10과 그 이후 버전에서 GCC에서 제공하는 내장 함수를 지원하지 않는 컴파일러로 컴파일 되었을 때 InnoDB는 이 라이브러리 함수를 사용하였다.
GCC, 윈도우, 솔라리스 함수와 같이 원자적 메모리 접근이 가능하지 않은 플랫폼의 경우 InnoDB는 뮤텍스와 읽기/쓰기 락을 구현하기 위해 P쓰레드 방식을 사용하고 있다.
MySQL이 시작될 때 InnoDB는 원자적 메모리 접근시 뮤텍스를 사용하는지, 혹은 뮤텍스와 읽기/쓰기 락을 사용하였는지, 혹은 둘 다 사용하지 않았는지에 대한 정보를 로그 파일에 남기고 있다. 만약 InnoDB를 구축하기 위해 어떤 툴을 사용하고 있던가, 원자적 동작을 지원하는 CPU를 대상으로 개발하고 있다면 InnoDB는 내장된 뮤텍스 함수를 사용할 것이다. 또는 비교&스왑 동작을 하는 쓰레드 식별자(pthread_t) 가 사용될 수도 있는데 이 경우 InnoDB는 읽기/쓰기 락을 구현할 때도 이 방식을 사용하게 된다.
